Implementing SVDQuant W4A4 on Blackwell — an FA4-skeleton, warp-specialized, TMEM, 2-CTA-persistent kernel walkthrough
How to keep a complex pipeline-synchronization state space from
deadlocking on Blackwell, by borrowing FlashAttention-4’s
synchronization scaffolding (explicit per-warp pipeline state +
warp specialization + persistent tile scheduler) instead of writing
your own state machine. A walk-through on this repo’s gemm_w4a4
kernel — re-architected from a 1-CTA stock CUTLASS port to a 2-CTA
persistent FA4-derived kernel — and the one-line SMEM-accounting bug
worth +198 % TF that was hiding behind a “runs fine” smoke.
Code: ultism/svdquant-kernels.
A lot of this post’s substance lives in the repo source — line numbers,
PTX, kernel docstrings, gotcha docs — best read alongside the repo
(and an AI that can navigate it).
1. Preface
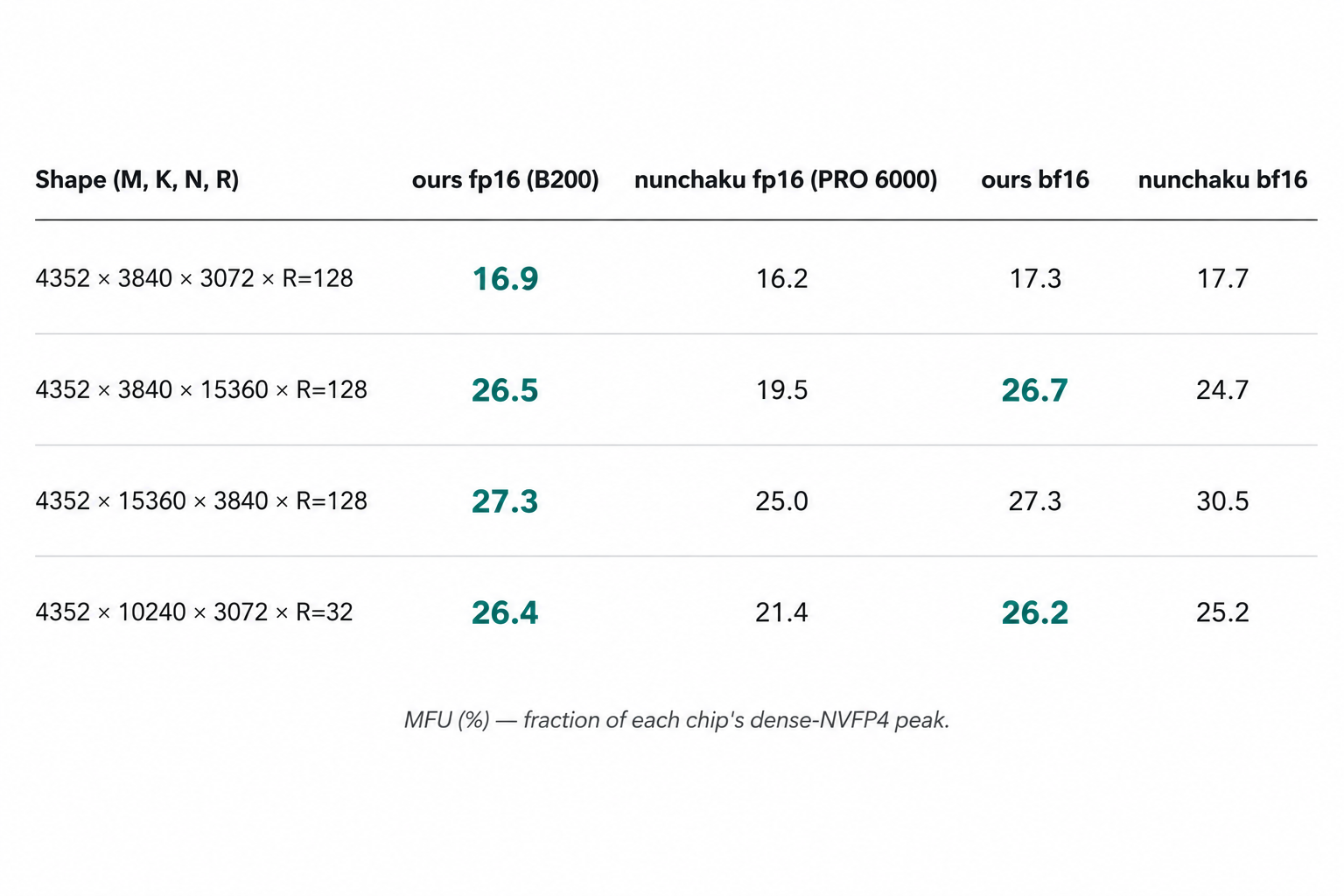
Numbers come from ncu’s
sm__pipe_tensor_cycles_active.avg.pct_of_peak_sustained_* counter —
how busy the tensor pipe was on each device’s own per-cycle ceiling,
clock-independent. We started with cross-arch MFU but had to drop
it: nunchaku only ships SM_120a/121a (consumer/workstation Blackwell,
see nunchaku/setup.py:41-64), there is no SM_100 binary, so the
comparison is inherently data-center-Blackwell vs consumer-Blackwell —
and consumer boost clocks swing wide enough that MFU readings drift
more than the kernel-quality signal we wanted (docs/gpu.md § Cross-arch
MFU caveat).
Read it: ours-fp16 and nunchaku-fp16 saturate their respective tensor pipes to within 0.2 pp on each card’s own per-cycle peak — both kernels push the hardware they sit on to roughly the same fraction of its ceiling. The 5.8× duration gap is the B200’s larger SM count and higher per-cycle FP4 peak doing its job, not a code-quality gap. nunchaku’s bf16 elapsed sits 9.2 pp above its fp16 elapsed because the fp16 path hits a register-pressure cliff (255 regs/thread + 2.28 M LMEM spills, full breakdown in §9.2); ours has no such cliff in either dtype.
Same B200, no LoRA / no affine / no next-quant, CUTLASS’s
dense_blockscaled_gemm_persistent.py at 2-CTA 256×256 lands at
45–63 % MFU. That same-device MFU is unaffected by the cross-chip
clock-drift problem and is the headroom that still matters.
The op is the compute-bound half of SVDQuant: NVFP4 scaled MMA + a small low-rank LoRA residual + a per-column affine. The math fits on one line; the implementation exercises essentially every primitive SM_100 / SM_103 adds over previous generations.
Two iterations of the kernel live in this repo. v1
(cute_kernels/gemm_w4a4/kernel.py, 1-CTA, monolithic @cute.kernel,
stock cutlass.pipeline.PipelineState) caps at ~27 % MFU on the
production shape; the Phase-1 attempt to lift it to 2-CTA via
cta_group=TWO got essentially zero benefit (28 % vs 27 %). v2_fa4
(cute_kernels/gemm_w4a4/kernel_v2_fa4.py, FA4-derived warp-specialized
3-pipeline, 2-CTA persistent) is the shipping surface that produces
the numbers above.
The most valuable single-line change in the whole project: halving
the per-CTA SMEM-byte estimate for the LoRA-up weight tile under
2-CTA mode. The kernel computes its SMEM budget at trace time —
“given this much shared memory per SM, how many in-flight K-blocks
can the main K-loop juggle, and how many stages of LoRA prefetch
can we afford?” The formula for the LoRA-up tile’s share was
hand-written, and it overlooked one thing: under 2-CTA mode the
hardware already shards that tile across the two CTAs in a cluster,
so each CTA’s actual on-chip allocation is half of what the formula
returned. The budget solver, fed that 2× overestimate, silently
cut the main K-loop pipeline depth in half (from 4 in-flight
K-blocks down to 2) to “make room” for shared memory that wasn’t
actually being used. Symptom: nothing — kernel compiled, ran, was
numerically correct, and just looked “a bit slow.” Fix: one extra
division by the cluster’s CTA-group size in that one line. Wall-clock
at the production shape: 566 TF → 1685 TF (+198 %), 4.2 % →
16.9 % MFU. ncu A/B at the same launch config: Duration −31.2 %,
SM Throughput +11.99 pp, SM Active Cycles −36.3 %. Commit 7296e90;
full data in §7.
This post walks both stories together, because they’re the same story: the kernel only exposes the LU SMEM bug after the FA4 rewrite makes 2-CTA actually work end-to-end, and the LU SMEM bug only matters because the FA4 rewrite was the thing that unblocked the budget solver in the first place.
2. Why this op, and why this post
The math:
y = scaled_mma(act₄, wgt₄) · wcscale + bias + lora_act_in @ lora_up
Inputs are NVFP4-packed (act, wgt: [M, K/2] uint8 with two E2M1
nibbles per byte; ascales, wscales: [K/16, *] FP8-E4M3 per-16-K-block
scales). lora_act_in @ lora_up is a small rank-R residual (R ≤ 128
in production, R=32 most common). wcscale and bias are per-output-
column. There’s no chained data flow, no softmax, no online correction:
one main MMA, one LoRA MMA, one fused affine.
Two design constraints frame everything that follows:
- SM_100 / SM_103 only. Consumer Blackwell SM_120a/121a is covered
by nunchaku (
nunchaku/setup.py:41-64lists its arch matrix). This repo exists to fill the data-center Blackwell gap, and Ampere through Hopper is also out of scope. So the kernel can assumetcgen05scaled-MMA, TMEM, 2-CTA dense MMA, TMA bundles, and the rest of the SM_100 toolbox unconditionally. - CuTe DSL Python, not CUDA C++. The Python DSL is NVIDIA’s
authoring path on Blackwell; same
cutlass-dslpackage upstream uses, ~10× less template boilerplate than the CUDA C++ CuTe headers. Real kernels JIT-lower through MLIR → PTX at first call. Trace-level checks work on any Linux box (setCUTE_DSL_ARCH=sm_100aif your local card lies about the arch); real execution needs B200/B300.
That’s the setup. The editorial claim of this post is that this op
is a better teaching vehicle than FA4 for Blackwell primitives.
FA4’s online softmax and S→P→O chained dataflow add real cognitive
tax — most of FA4’s complexity isn’t about Blackwell, it’s about
attention. SVDQuant W4A4 strips that away: same warp-specialized
mainloop, same persistent tile scheduler, same tcgen05 accumulators,
same TMA bundles, same 2-CTA partitioning — but the math is one
screenful. If you want to learn Blackwell primitives by reading a
real production kernel, this op is the cleaner read.
3. The Blackwell primitives this kernel uses
Treats the reader as fluent in CUTLASS 2.x + CUDA. Everything below is new on SM_100/SM_103, in roughly the order it gets exercised by the kernel.
3.1 tcgen05.mma scaled-MMA and the NVFP4 atom
NVFP4 is a block-scaled FP4 format: two E2M1 nibbles packed into a
byte for the values, plus one FP8-E4M3 scale per 16-element K block.
Effective precision is ~7 bits per value once the block scale is
applied. Blackwell’s tcgen05.mma.kind::mxf4nvf4.block_scale.scale_
vec::4X atom reads both packed operands and both scale tensors and
emits an FP32 accumulator into TMEM.
CuTe DSL exposes this via make_blockscaled_trivial_tiled_mma(...).
Worth knowing: it only exposes MXF4, NVFP4, and MXF8 scaled-MMA on
Blackwell — INT4 scaled-MMA was dropped at the ISA level when
NVFP4 landed. (Ascend’s cube unit still has INT4 MMA, which is why
this repo’s Ascend pod stays INT4 and the CUDA pod is NVFP4 — same
math at the framework level, format-specialized at the kernel level.)
The atom takes two scale inputs at runtime via
tiled_mma.set(tcgen05.Field.SFA, …) and .SFB. The scales live in
TMEM (not SMEM): the kernel cute.copys them from SMEM into TMEM
once per K-block of work, then issues the gemm. We use this in
kernel_v2_fa4.py:1339-1346:
tiled_mma.set(tcgen05.Field.SFA, tCtSFA[sf_kblock_coord].iterator)
tiled_mma.set(tcgen05.Field.SFB, tCtSFB[sf_kblock_coord].iterator)
cute.gemm(tiled_mma, tCtAcc, tCrA[kblock_coord], tCrB[kblock_coord], tCtAcc)
The first three lines are Python trace-time mutations of the
tiled_mma object — they hold for whatever cute.gemm site captures
them in the MLIR. The fourth line is the actual umma.commit that
fires on device.
Footnote on the “NVFP4” we use vs. the cuBLAS NVFP4 linear. The
full NVFP4 spec is two levels of scaling — a per-tensor FP32 scale
plus a per-16-element FP8-E4M3 block scale. nunchaku’s design, which
we inherit, uses a single level: the block scale only, with any
per-tensor scaling absorbed into the block scale (or into wcscale)
at calibration time. cuBLAS’s NVFP4 linear, by contrast, exposes
both levels at runtime. The two are mathematically equivalent when
the tensor scale is folded in offline; the difference is in what the
spec carries through to the runtime API, not in the achievable
precision. We follow nunchaku here because the LoRA + wcscale
machinery already absorbs the tensor scale naturally.
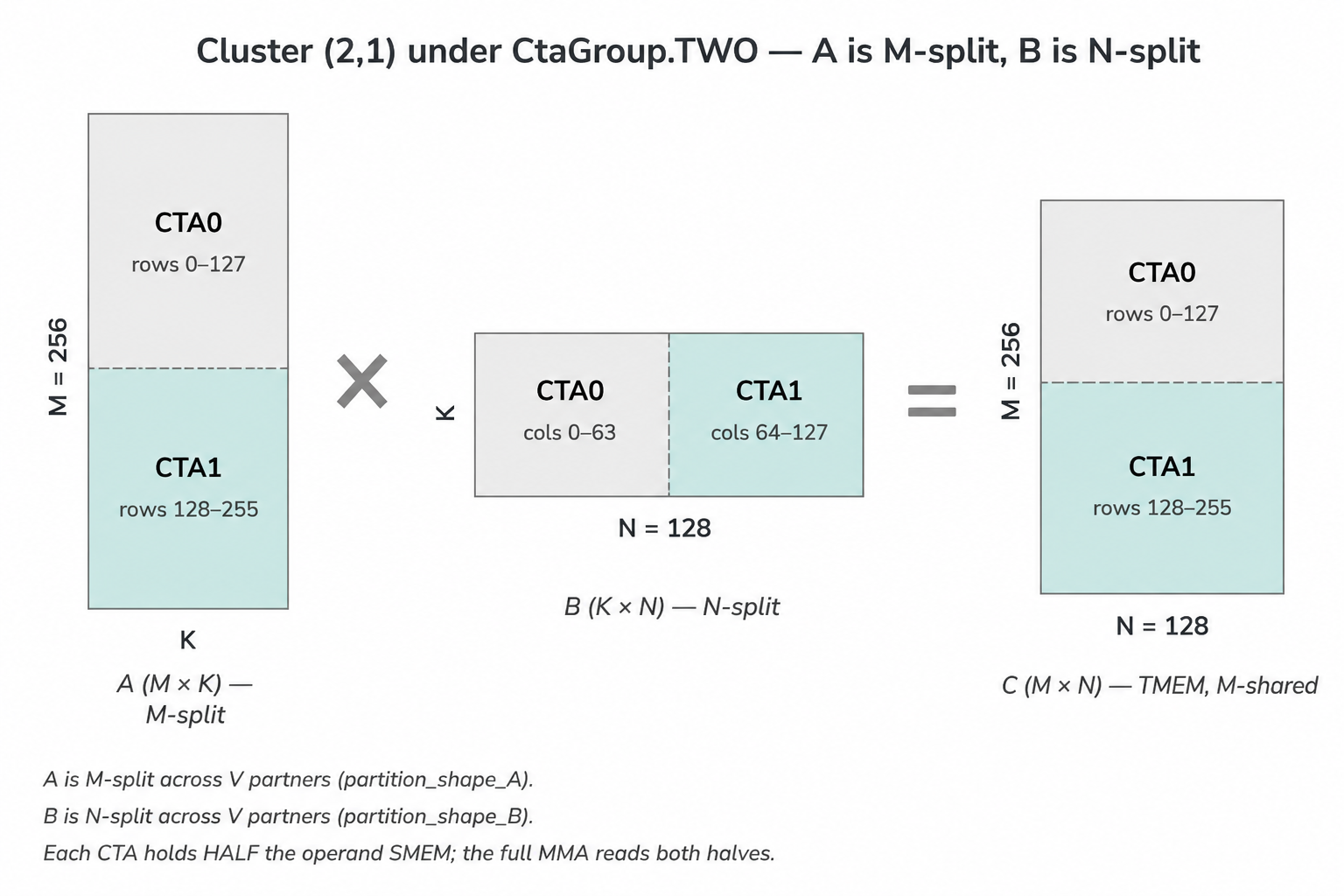
3.2 2-CTA dense MMA via cta_group=TWO
Two CTAs in a cluster_shape=(2, 1) cluster cooperate on a single
larger tile. The atom is constructed with CtaGroup.TWO, which
inserts a V (volume) axis of size 2 into the MMA’s thread layout.
Each CTA in the pair owns one half of the cluster-level work, but
both participate in every MMA issued by the leader CTA.
The cluster layout factors as (V, M, N, K):
cluster_shape_mn = (2, 1), CtaGroup.TWO:
cluster_layout_vmnk.shape = ((2,), 1, 1, 1)
rank=0 → flat coord (0, 0, 0, 0) ← leader CTA
rank=1 → flat coord (1, 0, 0, 0) ← follower CTA
(Reading the right index out of cluster_layout_vmnk to recover
the per-CTA M position under 2-CTA is the kind of code-understanding
trap that doesn’t belong in primitive-teaching prose; the write-up
is at docs/gotchas/cute_dsl.md:90-151 if you want it.)
The SMEM payoff. Under CtaGroup.TWO, the MMA atom’s
partition_shape_A halves A along M and partition_shape_B halves
B along N. So each CTA only needs to stage half the operand SMEM the
1-CTA atom would need — this is the “2xSM MMA: Shared Memory
Optimization” lever called out in the Modular
matmul-on-blackwell-part-3 post. CUTLASS uses it in
dense_blockscaled_gemm_persistent.py and the v2_fa4 main path uses
it for A and B (kernel_v2_fa4.py:465-468). The LoRA path’s LU
operand was meant to use it too — that’s §7.
3.3 TMEM as an addressable accumulator space
Pre-Blackwell, the accumulator of an MMA lived in registers and you
moved it through mma.sync PTX or cute::gemm. On Blackwell the
accumulator lives in tensor memory (TMEM) — a SM-local memory
region with its own allocator (utils.TmemAllocator), its own
deallocation barrier, and a 512-column-wide layout. Two implications:
- TMEM is shared between threads of a CTA in a way registers are
not. The single MMA warp issues
cute.gemmand any warp on the CTA can later read the TMEM cells viatcgen05.tmem_loadand feed them into the epilogue. This is what lets the 4-warp epilogue group read accumulators the 1-warp MMA group produced. - Two MMA atoms can target the same TMEM range. FA4’s
blackwell_helpers.gemm_ptx_partialtakes a rawacc_tmem_addr: Int32rather than acute.Tensor. Once you have the TMEM address, you can issue a second MMA withACCUMULATE=Trueagainst the same address, and the second MMA reads the first MMA’s result through the same TMEM cells. The β-interleave in §6 uses this to run main NVFP4 MMA and LoRA fp16 MMA into the same FP32 accumulator without going through GMEM or acute.Tensoralias.
TMEM budget on SM_100 is 512 columns max. NVFP4 block-scaled MMA
on a 256×128 tile takes 128 cols of accumulator + 16 cols SFA + 32
cols SFB ≈ 176 cols; doubling the accumulator (overlapping_accum for
the next-tile ping-pong) fits at tile_n=128 and busts at
tile_n=256. This is why num_acc_stage = 1 if tile_n == 256 else 2
on both sides (CUTLASS reference plus our kernel, see gotcha at
docs/gotchas/cute_dsl.md:231-287).
3.4 TMA, the extra_tx_count bundle, and the is_leader_cta gate
TMA copies are async, and they signal completion through
mbarrier arrivals. Each TMA bumps the barrier’s
expected_transactions (tx_count) by the number of bytes it
delivered; when the count is reached the barrier flips full and a
consumer can be released. CuTe DSL’s pipeline.PipelineTmaUmma.create
wraps this for the producer/consumer pattern most GEMM kernels want.
Two SM_100-specific knobs in the wrapper:
extra_tx_countfor bundling. Instead of one barrier per TMA, you can have one barrier protect multiple TMAs by summing their byte counts into a singletx_count. The main K-loop’sact + ascales + wgt + wscalesare all four issued under one barrier withtx_count = num_tma_load_bytes(kernel_v2_fa4.py:906-914). Saves three mbarrier slots and one barrier-wait per stage.is_leader_ctafor 2-CTA bookkeeping. UnderCtaGroup.TWO, only the leader CTA in the cluster pair callsarrive_and_expect_tx(the other CTA’s TMA participation is implicit intx_count×cta_group_size). If the follower also arrives, the barrier double-counts and deadlocks. CuTe DSL handles this insidePipelineTmaUmma.producer_acquireifcluster_layout_ vmnkis passed in — the kernel just hands it the layout and lets the wrapper gate.
3.5 StaticPersistentTileScheduler
The pattern: launch min(num_tiles, sm_count) CTAs and let each CTA
walk through tiles by tile_idx += grid_dim() until it falls off the
end. Saves launch overhead, keeps warps warm across tiles, lets the
TMA pipeline carry state between tiles.
Implementation footprint is tiny — FA4’s
tile_scheduler.py::StaticPersistentTileScheduler is ~30 lines, and
our equivalent is inlined into kernel_v2_fa4.py:885-892. The hard
part is not the scheduler; the hard part is making the rest of the
kernel’s state survive tile boundaries, which is §5.
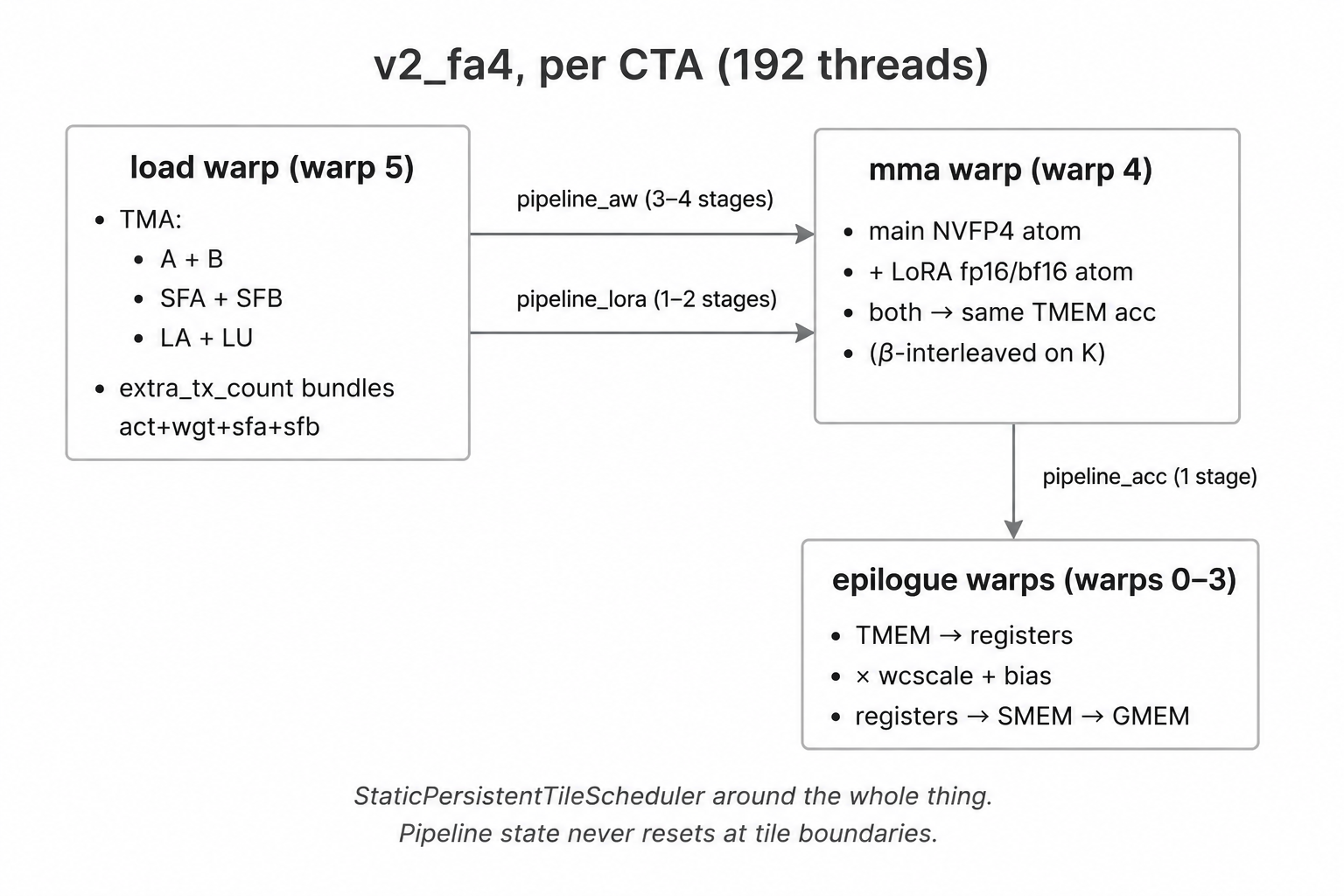
3.6 Warp specialization (preview)
One warp does TMA loads (load warp), one warp issues MMAs (mma
warp), four warps run the epilogue (epilogue warps). Total 6 warps
× 32 threads = 192 threads per CTA. Each warp has its own pipeline
state and advances it independently — there is no global “kernel
state.”
This is the structural pattern FA4 codified for tcgen05 + TMEM
kernels. The full picture (3 pipelines × 3 warp groups + per-warp
PipelineStateSimple) lands in §6.
4. v1 — the pre-FA4 baseline
The file at cute_kernels/gemm_w4a4/kernel.py is v1: main NVFP4
scaled-MMA + β-interleaved LoRA, 1-CTA only, monolithic @cute.kernel,
stock cutlass.pipeline.PipelineState. Its docstring is candid about
the lineage: ported from
cutlass/examples/python/CuTeDSL/blackwell/
dense_blockscaled_gemm_persistent.py, with the persistent
TileScheduler stripped, clusters > 1 stripped, TMA multicast stripped,
overlapping_accum stripped, and the tile_n ∈ {64, 192} SFB-shift
hacks stripped. Two shape-adaptive 1-CTA tilers: (128, 128) for
small M, (128, 256) otherwise.
v1 was the right first move: take a known-working CUTLASS example,
keep the parts of it that obviously generalize, get the LoRA β-
interleave running on the same TMEM accumulator (kernel.py:30-33
references the TV-layout match verification), ship a correctness-clean
kernel before optimizing.
4.1 What v1 does well
- Numerics are clean. Smoke 22/22 across {fp16, bf16} × {1-CTA} ×
R ∈ {32, 128, 256}. The LoRA β-interleave math (one MMA warp owns
the issue stream, LoRA atoms sprinkled every
stride = K_atoms // R_atomsmain atoms, both atoms write the same TMEM acc) is identical to v2_fa4’s — that part of the design is stable from v1 onward, seedocs/kernels/gemm_w4a4.md:26-115. - Aliased-tensor LoRA acc works. The two MMA atoms (main NVFP4
- LoRA fp16) hit the same TMEM cells via two
cute.Tensorobjects whose underlying address is the same. The TV-layout match between mainpartition_Cand LoRApartition_Cis verified at trace time so the two atoms actually write to the same lattice, not just the same byte range.
- LoRA fp16) hit the same TMEM cells via two
- Shape-adaptive tiler. Small-M shape (M=256) gets
(128, 128); large-M gets(128, 256). The (128, 256) variant getsnum_acc_stage = 1automatically because tile_n=256 busts the TMEM budget atnum_acc_stage = 2; (128, 128) gets the overlapping_accum ping-pong for free.
4.2 Where v1 hits the wall — the CUTLASS-baseline comparison
On the same B200, same shapes, v1 vs CUTLASS’s own
dense_blockscaled_gemm_persistent.py (main NVFP4 MMA only, no LoRA;
strictly what our v0 does):
| shape (M, K, N) | CUTLASS 1-CTA 128×256 | CUTLASS 2-CTA 256×128 | CUTLASS 2-CTA 256×256 | ours 1-CTA | ours 2-CTA Phase 1 |
|---|---|---|---|---|---|
| 4352 × 3840 × 3072 | 3847 TF 38.5 % | 4202 TF 42.0 % | 4545 TF 45.4 % | 1309 TF 13.1 % | 1185 TF 11.8 % |
| 4352 × 3840 × 15360 | 4167 TF 41.7 % | 5181 TF 51.8 % | 5836 TF 58.4 % | 2735 TF 27.4 % | 2599 TF 26.0 % |
| 4352 × 15360 × 3840 | 4096 TF 41.0 % | 5903 TF 59.0 % | 6339 TF 63.4 % | 2646 TF 26.5 % | 2964 TF 29.6 % |
| 4352 × 10240 × 3072 | 4174 TF 41.7 % | 5375 TF 53.8 % | 6074 TF 60.7 % | 2299 TF 23.0 % | 2350 TF 23.5 % |
(Source: cute_kernels/gemm_w4a4/README.md:154-160. CUTLASS columns
run the same op v1’s v0 mode does — main NVFP4 only, so the
comparison is apples-to-apples.)
Two facts the table makes hard to argue with:
- At the same tile (128×256, 1-CTA), CUTLASS is ~14 pp ahead. Persistent scheduler, multi-stage MMA/epilogue overlap, more careful pipeline discipline. None of that is impossible in v1’s architecture — it’s just not built.
- The 2-CTA Phase 1 attempt got essentially nothing. Our 2-CTA column lands within 1–3 pp of our 1-CTA column on every shape, sometimes slightly worse. CUTLASS’s 2-CTA 256×128 column — same FLOPs-per-atom as 1-CTA 128×256 — lifts by 10–18 pp on the same hardware. The 2-CTA mechanics work for CUTLASS; they don’t work in v1’s architecture.
4.3 The diagnosis
The minute you try to lift v1 to 2-CTA persistent, the state space the kernel has to track grows along five dimensions at once:
- Pipeline stages. N stages of A/B SMEM with one mbarrier per stage, one phase bit per stage, one index per stage.
- 2-CTA pair barriers. Every TMA barrier under
cta_group=TWOhas to know about both CTAs in the cluster, gate viais_leader_cta, and bakecta_group_sizeintotx_count. - Persistent tile loop. Tile boundaries don’t drain the pipeline; state survives from tile N to tile N+1.
- LoRA β second-MMA. A second MMA atom interleaved into the main K-loop, with its own producer/consumer cycle on the LoRA prolog SMEM.
- Epilogue correction chain. Eventually fused
× wcscale + biasin the epilogue, with its own SMEM staging for the per-column factors.
Stock cutlass.pipeline.PipelineState is implicit (state evolves
through its advance() method, hidden inside the
PipelineTmaUmma/PipelineUmmaAsync wrappers), branching (it picks
a different code path on each call based on the current phase), and
single-dimensional (one PipelineState per pipeline, one pipeline per
warp role). It handles dimension 1 cleanly. It does not compose with
dimensions 2–5 — and the empirical evidence is sharp: a prior
persistent port (kernel.py-class, commit 61905df) passed
correctness at 1-tile-per-CTA and hung 500× when each CTA processed
~20 tiles. That’s the classic signature of phase/state drifting
across tile boundaries: the state machine is correct for the first
loop iteration and then accumulates error from there.
The fix isn’t “tune the existing v1 harder.” The fix is to replace the state machinery entirely. That’s the next section.
5. Why FA4 — the scaffolding we adopted
FA4 (the Blackwell forward pass in Flash-Attention 4, source at
flash-attention/flash_attn/cute/) had already solved the
5-dimensional state-space problem for a different op: attention. The
solution was to make the pipeline state explicit and per-warp,
make the persistent tile loop the kernel’s outermost structure, and
factor every Blackwell-specific footgun into named primitives. We
didn’t take FA4’s math — there’s no online softmax in our op, no
S→P→O chained dataflow, no Q/K/V partitioning — but we took the
scaffolding wholesale.
5.1 What we adopted from FA4
- Warp-specialized mainloop (
flash_fwd_sm100.py). Separateload(),mma(), andepilogue()methods, each running on a designated warp range. Ourmmainherits FA4’s two-MMA-in-one-warp pattern (tiled_mma_qk + tiled_mma_pvin their code) — but where FA4 chains the two MMAs (QK output feeds PV input through TMEM), we point both MMAs at the same TMEM accumulator region for β-accumulation. Different math, same warp structure. PipelineStateSimple(pipeline.py). One state object per warp per pipeline. Single_phase_indexcounter —index = phase_index % stages,phase = (phase_index // stages) & 1. Pure divmod, no branchingadvance(). The_w_index_phasemixin lets each warp drive its own state without coordination. The copy-and-paste of_pipeline_simple.pylives atcute_kernels/gemm_w4a4/_pipeline_simple.py(82 lines).PipelineTmaUmmawithextra_tx_count+ leader-CTA gate. FA4’s override ofcutlass.pipeline.PipelineTmaUmma.createaddsextra_tx_count(multiple TMAs share one barrier) and anis_leader_ctagate (2-CTA-aware). Both are knobs we need; the upstream wrapper exposes them but the implicitPipelineStateflow doesn’t use them.StaticPersistentTileScheduler(tile_scheduler.py). 30 lines, drop-in. Grid clamped tosm_count,tile_idx += grid_dim().gemm_ptx_partial(blackwell_helpers.py). Takes rawacc_tmem_addr: Int32. Two MMAs can target the same TMEM region without going through acute.Tensoralias — which our v1 did do, by building twocute.Tensors that point at the same address. Works in v1 (single tile, one trace), but the alias trick is fragile under the persistent-loop ACCUMULATE state trace-freeze.AI/DEBUG_2CTA.md— FA4 ships a debugging-guide markdown file next to the kernel listing every 2-CTA footgun (tx_count ×cta_group_size, phase parity,producer_taildeadlock undercta_group=TWO,tcgen05.commitempty groups). Saved us a week of bring-up; we lift specific items intodocs/gotchas/cute_dsl.mdwhenever we hit one in practice.
5.2 What we did NOT take from FA4
This is the editorial part of the section. FA4 is an attention kernel; most of its complexity is attention complexity. Specifically:
- Online softmax. Not relevant to a GEMM. The running max + rescale isn’t a Blackwell pattern, it’s an attention pattern.
- S→P→O chained dataflow. FA4’s QK output (S) is softmaxed into P, which then feeds PV (the V matmul). That chain pins how the two MMAs use TMEM. Our β-interleave puts both MMAs into the same accumulator — they don’t chain, they accumulate. The MMA-warp structure is similar but the TMEM bookkeeping is much simpler.
- Q/K/V partitioning. Three tensor roles in attention; one weight, one activation, one LoRA pair here. Different.
The result is that adapting FA4’s scaffolding for SVDQuant W4A4 actually strips down the harder parts of FA4. If you’ve read FA4 and understood the warp-spec pattern, this kernel is a cleaner second example to read — fewer moving parts, the same primitives.
6. v2_fa4 — the rewrite
The current file is cute_kernels/gemm_w4a4/kernel_v2_fa4.py. It’s
the third real iteration of the FA4-derived rewrite: v0_fa4 (no LoRA,
scaffolding-only), v1_fa4 (= v0_fa4 + single-stage LoRA, kept as a
hidden code path for reference numbers), and v2_fa4+C1 (= v1_fa4 +
2-stage LoRA prolog + the × wcscale + bias epilogue + the LU SMEM
fix we’ll get to in §7). The kernel that ships is v2_fa4 with C1, post
LU SMEM fix; everything below describes that surface.
6.1 v0_fa4 — the scaffolding without LoRA
The first commit on the FA4-derived branch was kernel_v0_fa4.py:
FA4 skeleton, no LoRA, no wcscale/bias. Purpose: validate the new
state machinery in isolation before threading LoRA back in.
Numbers, on the production shape M=4352 K=3840 N=3072 fp16:
| 1-CTA | 2-CTA | |
|---|---|---|
| v0_fa4 | 7.7 % | 7.6 % |
(Source: cute_kernels/gemm_w4a4/README.md:183-189.) Lower than v1’s
27 % — but that’s expected. v0_fa4 is a partial-feature scaffold; it
doesn’t have multi-stage pipelining tuned yet, it doesn’t have the
overlapping_accum lever, and it’s reporting wall-clock that includes
the full set of FA4 patterns (multi-pipeline init, tile scheduler
overhead, the warp-spec barrier set) without the optimizations that
amortize them. We froze it as the v0/v1 reference (flag-gated on
enable_lora so the same file can run as either) and moved on.
The very first device-side run of v0_fa4 produced the cleanest bring-up bump in the whole project, so it gets its own subsection.
6.2 Bump (inline): the 9-minute hang on first smoke
Symptom: kernel launched on Modal, nvidia-smi showed the GPU
busy, no stdout for 9 minutes, then Modal’s container timeout fired.
No abort, no assert, no PTX error — just a clean stall.
Cause (root cause analysis in
docs/kernels/gemm_w4a4_fa4_v0_bringup.md:27-44): the MMA warp’s
single-stage pipeline_acc had its producer phase initialized to
Int32(0). After pipeline_init_arrive runs at kernel start, the
empty mbarrier is pre-arrived to parity 1. The MMA warp then calls
producer_acquire with phase 0 — which means “wait until the barrier
flips to parity 0.” But the consumer (epilogue warp) hasn’t run yet,
the barrier is still at parity 1, and the MMA warp blocks forever.
Fix: initialize acc_producer_phase = Int32(1). This matches what
stock cutlass.pipeline.make_pipeline_state(Producer, ...) returns
under the hood and what FA4’s own load() comment says
(“single-stage producer starts at 1”). Two-character patch:
# kernel_v2_fa4.py:1247-1253
# Single-stage pipeline_acc — phase bit only (XOR toggle).
# Producer starts at phase=1: `pipeline_init_arrive` pre-arms
# the empty barrier to parity=1, so the first `producer_acquire`
# with phase=1 returns immediately. Starting at 0 blocks forever
# (consumer never flips full, kernel hangs — was the 9-min hang
# on first smoke). Mirrors stock `make_pipeline_state(Producer)`.
acc_producer_phase = Int32(1)
Lesson worth carrying out of bring-up: under explicit
per-warp pipeline state, you own the initial-phase invariant. There
is no cutlass.pipeline.make_pipeline_state to call; the wrapper
isn’t doing it for you. Get the initial phase wrong by one bit and
the kernel hangs silently. The bring-up doc lists this and the
sibling “ACCUMULATE state freezes across persistent iterations” bump
(Bug 2/3, fixed by writing the K-tile loop as a Python range()
unroll rather than cutlass.range(unroll=1)).
6.3 Re-adding LoRA — the β-interleave on a shared TMEM accumulator
LoRA’s correction term lora_act_in @ lora_up is small (R ≤ 128).
Run serially against the main MMA (the “α” variant), it inflates wall
time by ~50 % on the worst production shape because tcgen05’s
async-issue queue depth is 4–8 atoms and a few-atoms-only LoRA pass
can’t keep it full (full analysis at
docs/kernels/gemm_w4a4.md:26-52). The fix is β: sprinkle LoRA atoms
into the main K-loop’s issue stream so the pipe never sees only
LoRA.
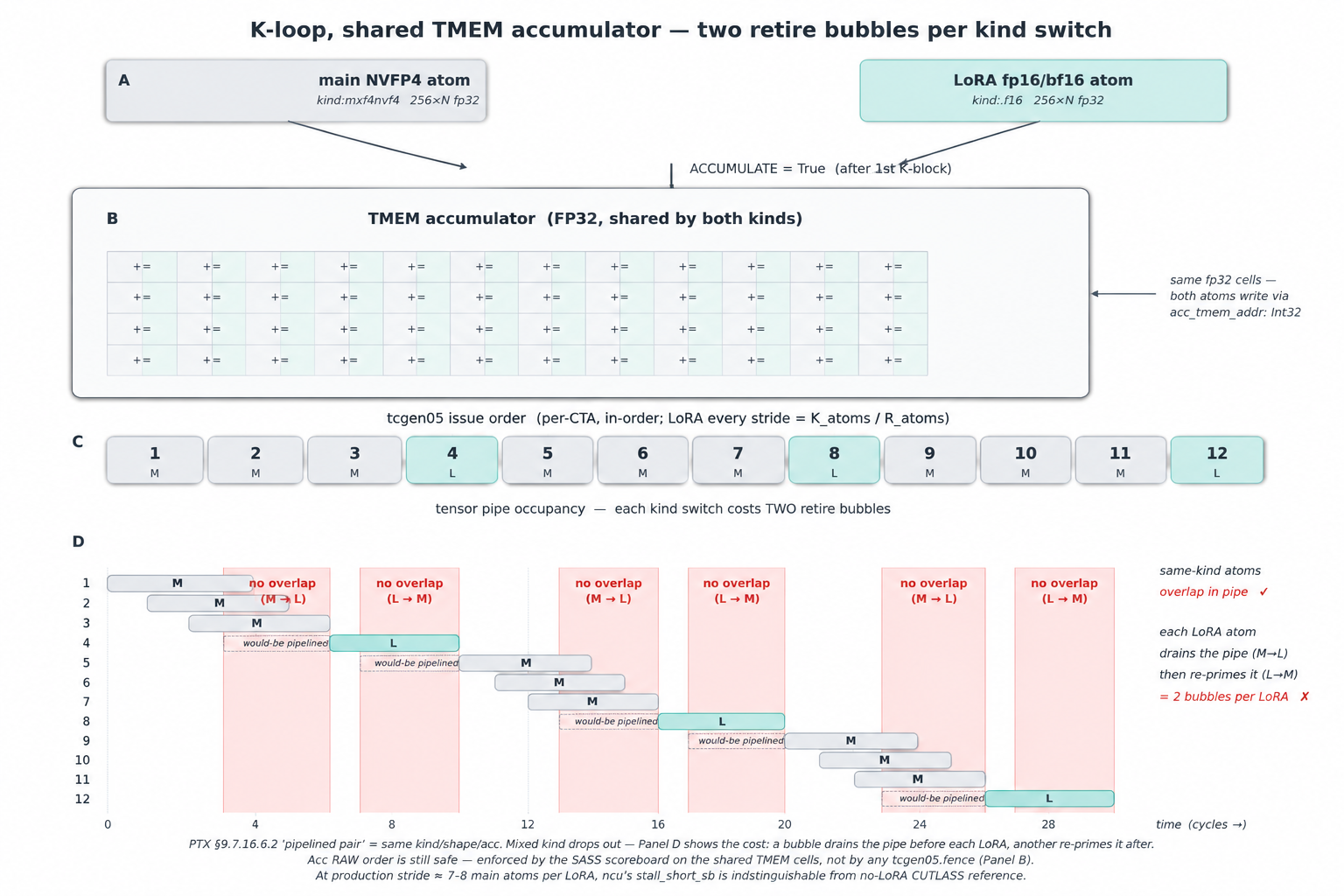
The mechanism rides on three Blackwell facts:
tcgen05honors the accumulator’s RAW dependency at SASS- scoreboard level. Both atoms write the same TMEM cells;ptxasmarks that as a data dependency and emits the scoreboard write/wait bits in each instruction’s control word, so the LoRA atom’sUTCHMMAretires only after the preceding mainUTCOMMA. No software fence required. (Worth flagging because the PTX manual’s §9.7.16.6.2 — “pipelined pair” requires samekind/shape/acc — reads as if a mixed-kind pair like ours needs atcgen05.fence. It doesn’t. That rule is about whether two atoms can overlap in the tensor pipe, not whether their writes to a shared accumulator stay in order; ordering lives one level below PTX. Confirmed against the cubin: zerotcgen05.fencein PTX, zeroFENCE.*betweenUTCOMMA/UTCHMMAin SASS; CUTLASS upstream is identical.)- Two atoms can target the same TMEM address. Via
gemm_ptx_partial(acc_tmem_addr: Int32), both atoms write to the same FP32 accumulator cells. Nocute.Tensoralias trick required (v1 took the alias route; works, but messier). - TV-layout match. The main NVFP4 atom and the LoRA fp16/bf16
atom partition the per-CTA
cta_tile_shape_mnkinto per-thread register fragments. For β to work, the “i-th element of thread t” must land in the same TMEM cell under both atoms. The match is checked at trace time (referenced in the kernel docstring atkernel_v2_fa4.py:1261-1270; the original verification ran viacute_kernels/gemm_w4a4/verify_tmem_layout.pyduring bring-up, both for1SM 128×256and2SM 256×256).
What we do pay is loss of pipeline overlap at the kind-switch
boundary — the LoRA atom serializes against its two neighboring main
atoms instead of overlapping with them in the tensor pipe.
Invisible at production density (one LoRA per stride = K_atoms /
R_atoms ≈ 7–8 main atoms at R=128): stall_short_sb — the
scoreboard stall that would catch it — measures 0.42 cyc/inst on
v2, indistinguishable from the no-LoRA CUTLASS reference at 0.55
(log/ncu_summary.md). The alternative — keeping main and LoRA on
separate accumulators and merging later — would add a TMEM-load
plus a TMEM-store per tile, which dwarfs the few cycles of overlap
we give up.
The interleave pattern itself is one extra branch per main atom in
the K-loop. stride = K_atoms // R_atoms controls how often a LoRA
atom fires; r_next and next_lora_at track which LoRA atom is up
and when. Source at kernel_v2_fa4.py:1309-1376:
The MLIR-tracing detail worth understanding: tiled_mma.set(
tcgen05.Field.ACCUMULATE, ...) is a Python trace-time mutation.
Each cute.gemm call site captures whatever the field is set to at
trace; runtime doesn’t re-execute the setter. So the K-tile loop has
to be fully Python-unrolled (for k_tile in range(k_tile_cnt):, not
cutlass.range(unroll=1)), because the second variant traces the
body once and would capture ACCUMULATE=False at the first kblock
site for every tile, wiping the accumulator on each tile boundary.
The current kernel uses Python range for exactly this reason — see
the long comment at kernel_v2_fa4.py:1294-1306.
6.4 Bump (inline): the 2-CTA LoRA regression
After we added LoRA back to the FA4 skeleton with a single-stage LoRA
prolog (the configuration we call v1_fa4), the 2-CTA path
regressed:
| (M=4352 K=3840 N=3072 R=128 fp16) | v0_fa4 (no LoRA) | v1_fa4 (1-stage LoRA) |
|---|---|---|
| 1-CTA MFU | 7.7 % | (not measured) |
| 2-CTA MFU | 7.6 % | 6.0 % |
(Source: cute_kernels/gemm_w4a4/README.md:185-189.) Going from
no LoRA to one stage of LoRA on the 2-CTA path made the kernel
slower. That’s pathological — even bad LoRA should be additive in
TFLOPS, not subtractive.
Diagnosis: LoRA SMEM (LA + LU) ate the budget. The single-stage
LoRA prolog was big enough that the budget solver (_compute_stages)
gave up num_ab_stage headroom for the main K-loop in exchange.
Fewer main-loop pipeline stages → fewer in-flight tcgen05 atoms →
SM% drops → wall time goes up. The fix has two parts; the obvious one
lands in §6.5, and the much bigger one lands in §7.
6.5 C1 — the 2-stage LoRA prolog
Raise num_lora_stage from 1 to 2 (C1 in the task tracker). Two
LA/LU buffers, ping-ponged. Cost: 2× the LoRA SMEM. Win: the prolog
cost amortizes across more main MMA iterations, the budget solver
gives back some main stages, the regression unwinds.
The numbers, before the LU SMEM fix was applied (so what C1 alone buys):
| shape (M=4352, K, N, R) | v1_fa4 (pre-C1) 2-CTA | v2_fa4+C1 2-CTA | Δ |
|---|---|---|---|
| K=3840 N=3072 R=128 | 6.0 % | 14.2 % | +8.2 pp |
| K=3840 N=15360 R=128 | 15.2 % | 18.6 % | +3.4 pp |
| K=15360 N=3840 R=128 | 17.0 % | 18.1 % | +1.1 pp |
| K=10240 N=3072 R=32 | 11.6 % | 26.1 % | +14.5 pp |
(Source: cute_kernels/gemm_w4a4/README.md:185-189.) C1 eliminates
the “2-CTA LoRA costs more than 1-CTA” anomaly — every shape gets at
least 1 pp, the worst-case shapes (small N or small R) jump
double-digit pp.
ncu mechanism, captured on Verda B200 (counter-unrestricted host) at the production shape:
| metric | v2 stage0 (LoRA off) | v2 stage1 (pre-C1) | v2 stage2 (C1) |
|---|---|---|---|
| duration (µs) | 42.0 | 77.1 | 69.6 |
| SM throughput % | 52.3 | 54.6 | 41.2 |
| hmma subpipe % (NVFP4 tcore) | 60.5 | 31.8 | 34.9 |
| warp cycles / issued inst | 15.0 | 18.6 | 25.9 |
| long_scoreboard cyc (L1TEX) | 10.6 | 13.8 | 21.8 |
(Source: cute_kernels/gemm_w4a4/README.md:209-217.) Three readings:
- The main MMA in isolation is fine. Stage 0 (LoRA off) hits 60.5 % hmma subpipe utilization — exactly what CUTLASS’s NVFP4 reference hits on the same hardware. The FA4 main K-loop is not the source of any gap.
- The LoRA prolog halves NVFP4 tensor-pipe utilization. Stage 0
→ stage 2 drops hmma 60.5 % → 34.9 % (−25.6 pp). DRAM throughput is
low across all configs (≤ 6 %), so it’s not bandwidth — it’s an
L1TEX wait, the
long_scoreboardcycles rise from 10.6 → 21.8. The LA/LU SMEM reads serialize against the main K-loop’s A/B SMEM consumption. - C1 is a partial fix. Stage 1 → stage 2 cuts duration 9.7 % (77.1 → 69.6 µs) and lifts hmma +3.1 pp. But the L1TEX wait per warp-cycle actually rises (13.8 → 21.8). The win is amortization: the 2-stage prolog spreads its cost across more main MMA iters per LoRA iteration. The latency root cause (LA/LU loads serializing against A/B SMEM consumption) is unmoved.
The full pre-C1 v1_fa4 → v2_fa4+C1 ~2.4× speedup on the smallest shape isn’t all C1, by the way — most of the win came from the LU SMEM fix that landed alongside C1 in the same commit window. C1’s standalone contribution per this ncu A/B is the −9.7 % / +3.1 pp piece. That’s useful background context for §7.
6.6 Fused × wcscale + bias epilogue
The last thing that distinguishes v2_fa4 from v1_fa4 is folding the per-output-column affine into the epilogue warp’s job. Math:
y[m, n] = acc[m, n] * wcscale[n] + bias[n]
wcscale and bias arrive as [N] tensors in c_dtype. The
epilogue warps read TMEM → registers, multiply-add, then store
SMEM → GMEM through TMA. The SMEM cost is negligible
(tile_n × c_dtype.width/8 = 256 or 512 bytes per buffer; v2 has
two buffers at most), and it’s accounted for in
wcbias_smem_bytes (kernel_v2_fa4.py:449-453). The pipeline_acc
consumer side grew to support reading the broadcast factors before
storing — the producer side is unchanged.
The motivation for folding rather than running a separate epilogue pass: no extra TMEM → SMEM → register round-trip, no extra TMA store, no extra mbarrier set. Cost is ~80 lines of epilogue-warp code.
7. The silent SMEM-budget bug — LU ÷ cta_group_size
The hero finding. Single-line patch, +198 % TF on the production
shape, and the entire detection story is “I wrote a cute.cosize
probe and ran it in 2 minutes.” This is the section that makes the
post worth writing.
7.1 The handwritten formula
Sm100GemmW4A4V2FA4._setup_attributes computes an estimate of how
many SMEM bytes the LoRA prolog needs, so _compute_stages can
deduct that from the per-SM SMEM budget before deciding how many
main num_ab_stages fit. The pre-fix arithmetic was:
# kernel_v2_fa4.py — handwritten, pre-fix
la_bytes = mma_inst_shape_mn[0] * R * lora_ab_dtype.width // 8 // cta_group_size
lu_bytes = mma_inst_shape_mn[1] * R * lora_ab_dtype.width // 8 # ← bug
lora_smem_bytes = (la_bytes + lu_bytes) * num_lora_stage
LA is the LoRA-down activation, dims [mma_tile_m, R]. LU is the
LoRA-up weight, dims [mma_tile_n, R]. Both feed into a LoRA MMA
atom built with cta_group=TWO under 2-CTA.
LA correctly divides by cta_group_size because the LoRA atom uses
partition_shape_A which splits A along M (M-shard, the same
mechanism that splits main A). The cluster has shape (2, 1), so
each CTA holds half the M.
LU was not divided by cta_group_size. The handwritten formula
assumed each CTA holds the full mma_tile_n × R of LU SMEM.
7.2 Why this is a bug
Under CtaGroup.TWO, the 2-CTA dense MMA atom also splits B
across the V partners — N-shard, via partition_shape_B. This is
the same “2xSM MMA halves the B tile” optimization Modular calls out
in the matmul-on-blackwell-part-3 post’s “Shared Memory
Optimization” section, and CUTLASS uses it in
dense_blockscaled_gemm_persistent.py without comment because it’s
the default behavior of partition_shape_B.
sm100_utils.make_smem_layout_b(tiled_mma_2cta, ...) returns a
per-CTA SMEM layout that’s already half of tile_n × tile_k. So when
LoRA’s make_smem_layout_b(...) builds the LU layout, the LU layout
is already half-sized per CTA. The handwritten estimate double-
counts.
7.3 Why the symptom is “nothing”
This is the dangerous part. Under-budgeted LoRA SMEM doesn’t crash —
it makes the budget solver pessimistic. The solver thinks LoRA SMEM
is consuming 16 KB more than it actually is, so it gives back 16 KB
to the main path by clamping num_ab_stage from 4 to 2. The kernel
compiles. It traces. It runs. It produces correct numerics. It just
runs with half the main K-loop pipeline depth it could have.
There’s no assert, no shape mismatch, no allocation failure. The
_compute_stages printout (if you turn it on) says “stage=2 fits” —
because at the pessimistic budget it really only fits stage=2. There
is nothing in the kernel’s behavior pointing at this bug. Wall-clock
is “slow but the kernel works”; ncu says “low SM%, high
long_scoreboard”; you spend a week tuning num_lora_stage and tile
geometry; nothing helps.
7.4 The two-minute probe
The fix-detection story is the part worth carrying out. cute.cosize
operates at trace time, returns an Int32, and reports the actual
SMEM cosize of a layout — exactly the quantity the handwritten formula
is trying to estimate. Drop a print into _setup_attributes:
print("la_one =", cute.cosize(slice_(self.la_smem_layout_staged,
(None, None, None, 0))))
print("lu_one =", cute.cosize(slice_(self.lu_smem_layout_staged,
(None, None, None, 0))))
Captured output (production shape, R=128, fp16, 2-CTA):
[PROBE96] num_lora_stage=2 cta_group_size=2
[PROBE96] la_one cosize=16384 -> 32768 B (handwritten 32768 B, factor 1.000)
[PROBE96] lu_one cosize=8192 -> 16384 B (handwritten 32768 B, factor 0.500)
LA matches handwritten (factor 1.000). LU is exactly half (factor 0.500). Bug found, 120 seconds of work.
7.5 The fix
One extra // self.cta_group_size:
# kernel_v2_fa4.py:429-444 — post-fix
lora_smem_bytes = 0
if cutlass.const_expr(self.enable_lora):
la_bytes = (self.mma_inst_shape_mn[0] * self.R
* self.lora_ab_dtype.width // 8) // self.cta_group_size
lu_bytes = (self.mma_inst_shape_mn[1] * self.R
* self.lora_ab_dtype.width // 8) // self.cta_group_size
lora_smem_bytes = (la_bytes + lu_bytes) * self.num_lora_stage
Commit 7296e90. The in-code comment at lines 429-444 cites the
probe artifact and the gotchas-file entry at
docs/gotchas/cute_dsl.md:289-347.
7.6 The before/after at the production shape
Same bench_gemm_v2_fa4_c1.py benchmark, fp16, 2-CTA,
M=4352 K=3840 N=3072 R=128, pre-fix on B300 vs post-fix on B200
(absolute TFLOPS is cross-card comparable; B200 has the lower NVFP4
peak of the two, so a “same TF” reading would still mean we got
faster against the weaker card):
| metric | pre-fix | post-fix | Δ |
|---|---|---|---|
| TFLOPS | 566 | 1685 | +198 % |
| MFU (B200 10 PFLOPS NVFP4) | 4.2 % | 16.9 % | +12.7 pp |
(Source: docs/gpu.md:286-296.) And the ncu A/B at the same launch
config on the same Verda B200 instance (HEAD^ vs HEAD = commit
7296e90, kernel swapped on disk between runs, num_lora_stage=2,
single launch):
| metric | pre-LU-fix | post-LU-fix | Δ |
|---|---|---|---|
| Duration | 46.69 µs | 32.13 µs | −14.56 µs / −31.2 % |
| Compute (SM) % | 41.63 | 53.62 | +11.99 pp |
| Memory % | 25.58 | 38.91 | +13.33 pp |
| L1/TEX Cache % | 28.50 | 44.75 | +16.25 pp |
| L2 Cache % | 24.57 | 36.18 | +11.61 pp |
| DRAM % | 5.04 | 7.31 | +2.27 pp |
| SM Active Cycles | 72 433 | 46 126 | −36.3 % |
| Memory Throughput | 386 GB/s | 561 GB/s | +45 % |
| Grid / Block | 148 / 192 | 148 / 192 | identical |
(Source: docs/gpu.md:393-403.) Reads cleanly: same launch shape,
same occupancy, but with num_ab_stage lifted 2 → 4 the SM-side
pipeline stays fed → SM% jumps +12 pp, SM Active Cycles drop 36 %.
L1/TEX and L2 throughput rise proportionally because the TMA producers
now have more in-flight buffers to fill — it’s not “less bandwidth
needed,” it’s “the bandwidth is more evenly used across the kernel’s
wall-time.” DRAM stays low (compute-bound regime preserved).
7.7 Why this generalizes — the teaching content
The bug is specific (lu_bytes doubled). The pattern is general: any
handwritten SMEM-budget arithmetic feeding the stage solver, for an
operand whose SMEM came from make_smem_layout_{a, b}(tiled_mma_2cta,
...), must divide by cta_group_size along the partitioned axis.
A is M-split (partition_shape_A halves along M); B is N-split
(partition_shape_B halves along N). Both are halved per CTA under
2-CTA, just along different axes.
Why people write handwritten budget arithmetic at all: _compute_
stages needs an upfront byte estimate before the SMEM layout for
the operand has been allocated (the layout depends on the stage count,
which depends on the budget — circular). The handwritten formula
breaks the cycle, but it’s easy to get the cta_group split wrong on a
non-main operand.
The robust alternative: build the layout, read back cute.cosize,
and use that as the budget input. Slightly more code but
hardware-truth by construction. Either approach works; the failure
mode to avoid is “handwritten formula + nobody ever cross-checked
against cute.cosize.”
The gotcha at docs/gotchas/cute_dsl.md:289-347 writes this up as a
pattern for future-us, with the probe template inline, the symptom
description (“no assert fires; numerics are still correct; perf is
just lower than it should be”), and the apply guidance (“Anywhere you
handwrite an SMEM-budget estimate for an operand that comes from
make_smem_layout_{a, b}(tiled_mma_2cta, ...), divide by
cta_group_size. Both A and B are halved under 2-CTA, just along
different axes.”).
8. Reading ncu like a Blackwell kernel author
The LU SMEM finding would have read as wall-clock noise without ncu —
14 µs out of 47 µs is real, but on Modal (where ncu is blocked, see
below) you’d have looked at a “slow” wall-clock and a “fine”
torch.profiler activity trace and concluded “kernel needs tuning”
without any specific direction to tune. The C1 mechanism story
(prolog amortization vs latency reduction) is even harder to read
without ncu — duration goes down, you ship, you never know that
long_scoreboard cycles per warp actually rose. So this section is
the methodology summary.
8.1 Counter access — Modal blocks, Verda allows
The split written up in CLAUDE.md execution-environment matters for
anyone trying to reproduce or extend this work:
- Modal (the fast-iteration host) has
NVreg_RestrictProfilingToAdminUsers=1set at the kernel-module level.torch.profiler(activities=[CUDA])(CUPTI Activity) works and gives per-kernel wall time with launch overhead stripped.nsys --trace=cuda,nvtxgives the kernel timeline. Anything that reads perf counters fails withLibraryNotLoaded:ncu,nsys --gpu-metrics-device,nvmlcounter queries. - Verda (the deep-trace host) unrestricts counters.
ncu --set detailedreports the SOL breakdown, the pipe utilization, the stall reasons. Workflow: iterate on Modal, pull a single kernel onto Verda only when wall time + activity trace can’t explain a delta.
8.2 The most copy-pasted thing — hmma is the NVFP4 tensor pipe
tcgen05 UTCQMMA executes on the hmma subpipe in ncu’s metric
tree. There is no standalone qmma_* counter. If you grep for qmma
you get nothing and waste an afternoon. The metric you want is:
sm__pipe_tensor_subpipe_hmma_cycles_active.avg.pct_of_peak_sustained_active
It covers HMMA + UTCHMMA + UTCQMMA + UTCOMMA all rolled together. For FLOPs split by accumulator dtype:
sm__ops_path_tensor_op_utcqmma_src_fp4_fp6_fp8_dst_fp32
sm__ops_path_tensor_op_utcqmma_src_fp4_fp6_fp8_dst_fp16
sm__ops_path_tensor_op_utcomma_src_fp4_dst_fp32 # separate FP4-only path
--section ComputeWorkloadAnalysis auto-pulls the subpipe breakdown.
UTCQMMA work shows up under “HMMA Pipe” in the SOL “Compute (SM) Pipe
Utilization” panel. Source for the full list: docs/gpu.md:105-127.
8.3 The SOL breakdown you want to read for a 2-CTA UMMA kernel
The C1 ncu table in §6.5 has the canonical rows. Reading guide:
- SM throughput % — how busy the SM pipes were on average. For a compute-bound NVFP4 GEMM this should be high; if it isn’t, look at hmma % to see whether the tensor pipe specifically is busy.
- hmma subpipe % — how busy the NVFP4 tensor pipe was. This is the number that matters. CUTLASS’s reference hits ~60 % at the production shape; v0_fa4 (no LoRA) hits 60.5 % (parity in isolation); v2_fa4+C1 (with LoRA) sits at 34.9 % (LoRA prolog drag).
- warp cycles / issued inst — average cycles per emitted
instruction. Inverse of IPC. A rise here means the kernel is
stalling more per instruction; cross-check against
long_scoreboard cyc(L1TEX wait) to attribute the stall. - long_scoreboard cyc (L1TEX) — average cycles a warp spent waiting on an L1TEX (SMEM) load. The dominant stall reason for our LoRA-on configurations.
The pattern to learn: hmma % being lower than CUTLASS’s reference is
not the same problem as long_scoreboard cycles being high. The
first says “the tensor pipe was idle”; the second says “the warp had
no work to issue.” Both can be true; they take different fixes.
8.4 The trace-time cute.cosize probe pattern
The single tool that unblocked the LU SMEM finding. Two pieces of mechanism:
- CuTe layouts know their cosize at trace time. The expression is
cute.cosize(layout)(or a sliced layout, as inslice_(self.lu_ smem_layout_staged, (None, None, None, 0))to drop the stage dimension). - Printing it from inside
_setup_attributes(which traces at compile time) emits the value to the console before the kernel runs. So you don’t need device-side instrumentation; the diagnosis surfaces at trace time, with one print.
Template, from docs/gotchas/cute_dsl.md:319-324:
print("la_one =", cute.cosize(slice_(self.la_smem_layout_staged,
(None, None, None, 0))))
print("lu_one =", cute.cosize(slice_(self.lu_smem_layout_staged,
(None, None, None, 0))))
Compare each to the handwritten value. Ratio 1.0 → match. Ratio 0.5 or 2.0 → operand split or unsplit on an axis you weren’t accounting for. Two minutes of work, surfaces the entire class of “handwritten- budget-misestimate” bugs.
9. Calibration — where this kernel actually sits
Two reference points; two different things they tell us.
9.1 The honest ceiling — CUTLASS NVFP4 on the same B200
CUTLASS’s own dense_blockscaled_gemm_persistent.py is main NVFP4
MMA only (no LoRA, no wcscales, no bias). Same atoms, same hardware.
At the production-shape row (M=4352 K=15360 N=3840, the K-heavy
shape):
| variant | MFU |
|---|---|
| CUTLASS 1-CTA 128×256 | 41.0 % |
| CUTLASS 2-CTA 256×128 | 59.0 % |
| CUTLASS 2-CTA 256×256 | 63.4 % |
| v2_fa4+C1+LU-fix, fp16 2-CTA | 27.3 % |
| v2_fa4+C1+LU-fix, bf16 2-CTA | 27.3 % |
(Sources: cute_kernels/gemm_w4a4/README.md:156-160 for CUTLASS;
docs/gpu.md:316-318 for v2_fa4 fp16/bf16.) Two takeaways:
- The honest NVFP4 ceiling on this hardware is ~60 % MFU, not the 30–40 % range that’s easy to quote from memory. That’s the number to calibrate against, not “100 %.”
- We sit ~35 pp below that ceiling, doing more work per tile —
LoRA β-interleave +
× wcscale + biasepilogue + LU/LA TMA prolog. CUTLASS does none of that. 27 % MFU on the full SVDQuant op is a reasonable B200 first pass for a CuTe DSL kernel that hasn’t yet ported the remaining FA4-class optimizations (overlapping_accum at tile_n=128, the tile 256×256 path with the matchingnum_acc_stagebudget surgery). The remaining 35 pp is the work in §10.
This is not the comparison that says “we’re slow.” It’s the comparison that says “here’s how much room is on the table; here are the next things to take from the table.”
9.2 The implementation-quality reference — nunchaku on RTX PRO 6000
nunchaku NVFP4 is gated on __CUDA_ARCH__ >= 1200 (SM_120a/121a, see
nunchaku/setup.py:41-64), so we can’t run it on B200 — there is
no nunchaku binary for SM_100. We run it on RTX PRO 6000 Blackwell
Server Edition (SM_120a) as an implementation-quality reference,
not a ceiling.
§1’s table is the apples-to-apples readout: ncu
sm__pipe_tensor_cycles_active.avg.pct_of_peak_sustained_* at the
production shape M=4352 K=3840 N=3072 R=128. Three numbers per row,
three things they tell you:
- elapsed % is the same (45.2 vs 45.4). Over the kernel’s wall-clock, both kernels saturate their respective tensor pipes to within 0.2 pp. This is the kernel-quality readout — each side pushes the hardware it sits on to the same fraction of its own per-cycle ceiling.
- active % differs (52.0 vs 58.8 on fp16). Over cycles when the
SM has work, nunchaku’s hand-PTX packs more tensor work per active
cycle; ours has more bubble cycles. This is the structural
DSL-vs-PTX codegen gap called out in
docs/gpu.md:79-103: nunchaku’s MMA is inline PTX (mma_earlycuda.cuh), two separately hand-tuned paths for fp16 and bf16 with different register packing and acc-precision choices; ours goes through onetcgen05atom withab_dtypesubstitution — same MLIR lowering for both. Closing the active % gap likely requires dropping to inline PTX, out of scope. - 5.8× duration gap is hardware capability: B200 SM_100 has more SMs and a higher per-cycle FP4 peak than PRO 6000 SM_120a. Not a code-quality readout.
Why we don’t quote cross-arch MFU here. MFU (FLOPS / device peak)
needs a stable device peak. Consumer Blackwell (PRO 6000, RTX 50)
sustained clocks swing wide with thermal envelope and per-die
binning — the “peak FLOPS” denominator in the spec sheet is one
specific clock, and the runtime drifts above or below. A 4-shape
cross-arch MFU table previously lived in this section; we pulled it
after re-running and finding the clock-drift signal exceeded the
kernel-quality signal. docs/gpu.md § Cross-arch MFU caveat is the
fuller writeup.
A brief note on nunchaku’s fp16 column. The 9.2 pp gap between
nunchaku fp16 elapsed (45.4 %) and nunchaku bf16 elapsed (54.6 %)
inside their column is a register-pressure cliff: their fp16
hand-PTX hits 255 regs/thread + ~2.28 M LMEM spills + 101 % spill
overhead; the bf16 path is 248 regs and zero spill. The 7-register
difference is “fits on-chip” vs “doesn’t.” Ours has neither cliff —
single tcgen05 atom + ab_dtype substitution goes through the
same MLIR lowering for both dtypes, so our fp16 elapsed ≈ our bf16
elapsed. This is a property of their reference’s codegen on
consumer Blackwell, not a property of our kernel.
Reports: log/ncu_v2_postLUfix_4352_3840_3072_R128.ncu-rep (B200),
log/ncu_nunchaku_4352_3840_3072_R128_{fp16,bf16}.ncu-rep (Verda
RTX PRO 6000, sm_120a).
10. What’s still on the table
Levers ordered by ROI on what we know now.
- bf16 register tuning. The one shape where nunchaku still leads bf16 (−3.2 pp at K=15360, N=3840) is the DSL MLIR lowering ceiling on bf16. The route forward is inline-PTX for the bf16 LoRA atom or a more aggressive scheduler hint. Bounded gain, ~3 pp.
- Wave quantization. Production shapes land at non-integer “waves per SM” — a tile-geometry tweak can recover a small percent. Cheap to A/B.
num_lora_stage=3is dead. Post-LU-fix it’s measured slower: the budget solver buys the extra LoRA stage by giving up two mainnum_abstages, and the main K-loop loses more than the LoRA prolog gains. The task tracker had two follow-ups in this direction (deeper LoRA pipeline, multicast LoRA TMA); both are deprecated (docs/gpu.md:357-381). Real bottleneck has moved to main K-loop / TMEM occupancy.- Closing the gap to CUTLASS 2-CTA 256×256 (~60 % MFU) — the
remaining 35 pp. Two FA4-class optimizations we haven’t ported yet:
overlapping_accumattile_n = 128.num_acc_stage=2for ping-pong between two acc TMEM buffers, hiding epilogue latency under the next tile’s MMA. Available only attile_n = 128because attile_n = 256the TMEM budget busts (gotcha atdocs/gotchas/cute_dsl.md:231-287). Needs MMA + epilogue warp surgery (dynamic TMEM stage index, every-2-advances phase flip).- Tile 256×256. Bigger MMA per tile, fewer tile-boundary stalls, less epilogue-launch overhead per FLOP. Mutually exclusive with overlapping_accum on the current TMEM budget. Worth A/Bing; modest ≤ 4 % MFU gain on big K·N, loses 3–11 % on small M / small K·N.
- Out of scope. Next-layer NVFP4 quant in the epilogue — needs
vLLM-level frame intrusion to wire the next layer’s
smooth_factorinto this layer’s quantize step. Same category asfuse_glu, and the architecture-scope decision is recorded indocs/architecture.md:76-100.
11. Where the code lives, and thanks
Code:
cute_kernels/gemm_w4a4/kernel.py— v1, pre-FA4 reference. 1-CTA, monolithic@cute.kernel, stockcutlass.pipeline.PipelineState.cute_kernels/gemm_w4a4/kernel_v0_fa4.py— FA4 scaffolding without LoRA. Frozen as the v0/v1 reference, flag-gated onenable_lora.cute_kernels/gemm_w4a4/kernel_v2_fa4.py— production. Main NVFP4- β-interleaved LoRA on shared TMEM + fused
× wcscale + biasepilogue + the LU SMEM fix.
- β-interleaved LoRA on shared TMEM + fused
cute_kernels/gemm_w4a4/README.md— design state, staging table, CUTLASS-baseline table, FA4-rewrite lineage, nunchaku cross-arch reference.cute_kernels/gemm_w4a4/_pipeline_simple.py— the 82-line copy of FA4’sPipelineStateSimplewe depend on.
Reference docs in this repo:
docs/gpu.md— canonical numbers (perf tables, ncu A/B, stage sweep, hmma routing).docs/gotchas/cute_dsl.md— silent-bug traps on the CuTe DSL path, including the LU ÷cta_group_sizeentry that grounded §7.docs/kernels/gemm_w4a4.md— the kernel design doc (β-interleave math, TMEM layout, warp roles, tile choice).docs/kernels/gemm_w4a4_fa4_v0_bringup.md— bring-up history, the 9-min hang and theACCUMULATEstate trace-freeze.
Key commits referenced in this post:
7296e90— the LU SMEM fix (§7).4a2d068— the ncu A/B that quantified the LU SMEM win.c0d8e9e— the post-fix MFU table vs nunchaku.61905df— the 500× hang on the prior persistent port.8f91240— the C2 patch (deferpipeline_lora.consumer_waitinto the K-loop inject site), mentioned in §6.
Cross-link: the Ascend (Atlas A3) side of the same op lives at
csrc/kernels/gemm_w4a4/ and uses INT4 + AscendC; the math is the
same. The architecture rationale for the format split is in
docs/architecture.md and CLAUDE.md.
Thanks. To Verda for the B200 image with unrestricted ncu — the
LU SMEM fix would have read as wall-clock noise on a counter-
restricted host, and the C1 mechanism analysis literally required
counter access. To Tri Dao’s Flash-Attention 4 for the
warp-spec scaffolding pattern that made the entire FA4-derived
rewrite possible. To NVIDIA’s CUTLASS team for both the
dense_blockscaled_gemm_persistent.py reference and the Modular
matmul-on-blackwell-part-3 write-up that named the
“2xSM MMA halves the B tile” mechanism in plain English.
Found a bug, a number that doesn’t line up, or an under-explained
primitive? File an issue against this repo, or send a patch into
docs/gotchas/cute_dsl.md — that’s the file these findings end up in.